
CAN - A simple, efficient and scalable contrastive masked autoencoder for learning visual representations
Published:
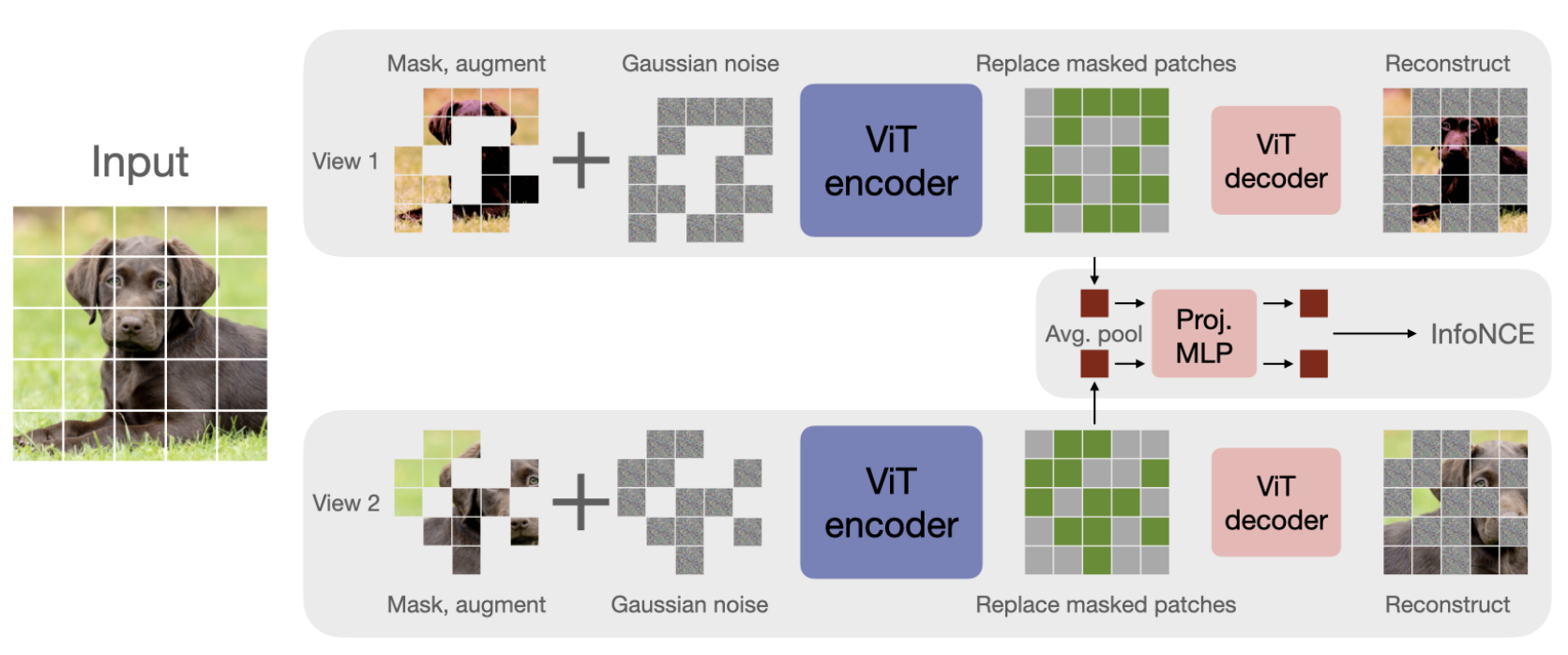
In my opinion, a very neat paper that combines several ideas from self supervised learning (SSL), namely contrastive loss (most notably, SimCLR [1]) reconstruction of masked patches (most notably “Masked Auto-encoders Are Scalable Vision Learners” [2]) and denoising autoencoder. Their pipeline is summarized in the figure below and works as follows: given an input image, generate 2 different views by applying augmentations, mask 50% of the patches, add Gaussian noise to the unmasked patches and feed the resulting noisy masked image to a ViT encoder. Now, we take the encoding of the unmasked patches, perform mean pooling, pass to a light MLP and apply contrastive loss (hence, the “contrastive” in the title). The encoded “patch image” is then passed to a ViT decoder to perform reconstruction of the masked patches and denoising of the unmasked noisy patches, which gives us the both reconstruction loss and the denoising loss.
| Arxiv, , Keywords: Self-supervised Learning, Contrastive Learning, Computer Vision, Venue: Under review |
|---|
 |
|---|
| The CAN framework:Two views of an image are generated, 50% of patches randomly masked in each, and noise is added to patches. An encoder is trained to solve three tasks: 1) Reconstruction: encoded patches are passed to a decoder that reconstructs missing patches, 2) Denoise: reconstructs the noise added to unmasked patches, and 3) Contrast: pooled patches are passed to a contrastive loss, using in-batch samples as negatives |
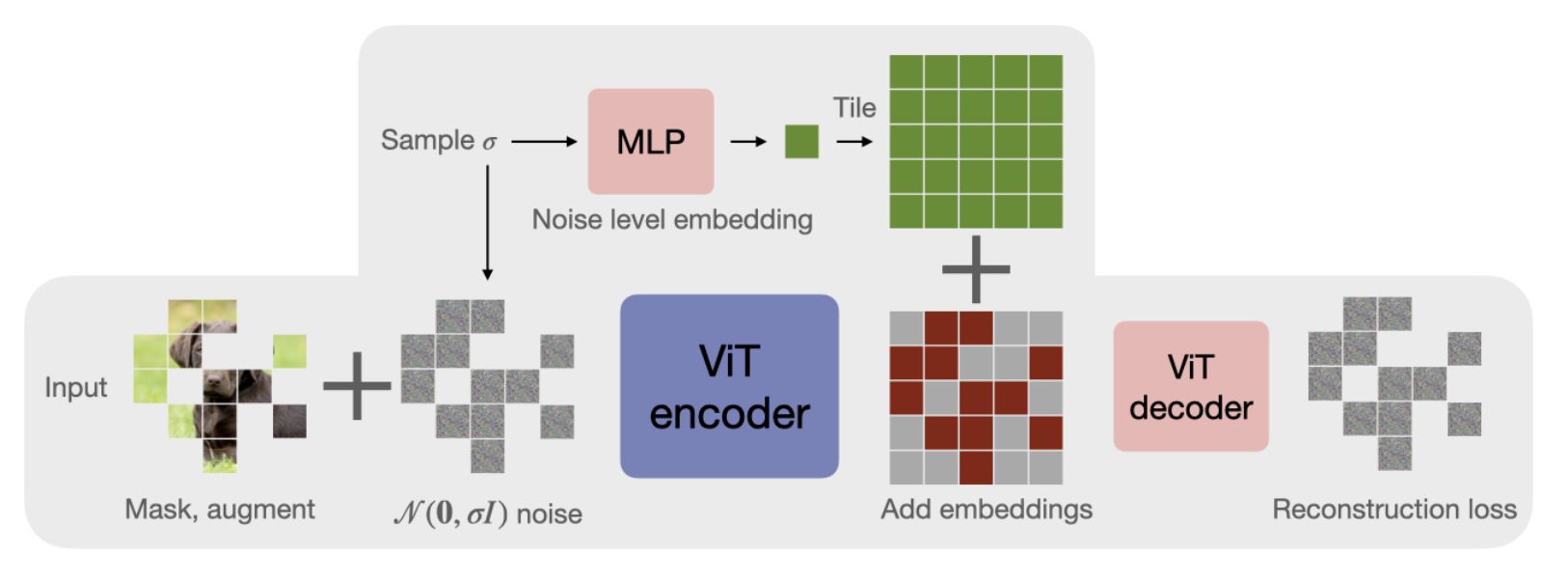
Motivated by diffusion transformers[3], the method provides the decoder with information about the noise level. Now, as the noise is modelled a simple zero mean Gaussian with standard deviation $\sigma$, the noise level information can be simply encoded by taking a sinusoidal embedding of $\sigma$, passing it to a light MLP to produce a (learned) embedding for $\sigma$ which is added to the noised patches before feeding those to the decoder. Below is a figure describing this process:
 |
|---|
| Denoising: Both the encoded patches and the noise level $\sigma$ are passed to the decoder by passing $\sigma$ through an MLP, and adding the result to each embedded token. |
The authors provide an ablation of this component which demonstrate that simply adding noise as an augmentation also improves the performance of the system even without the denoising loss. However, adding the denoising loss without incorporating the noise level information provides worse results while incorporating it outperforms noise augmentation, demonstrating the necessity of this component (see table 1 and ablation discussion in section 3.4).
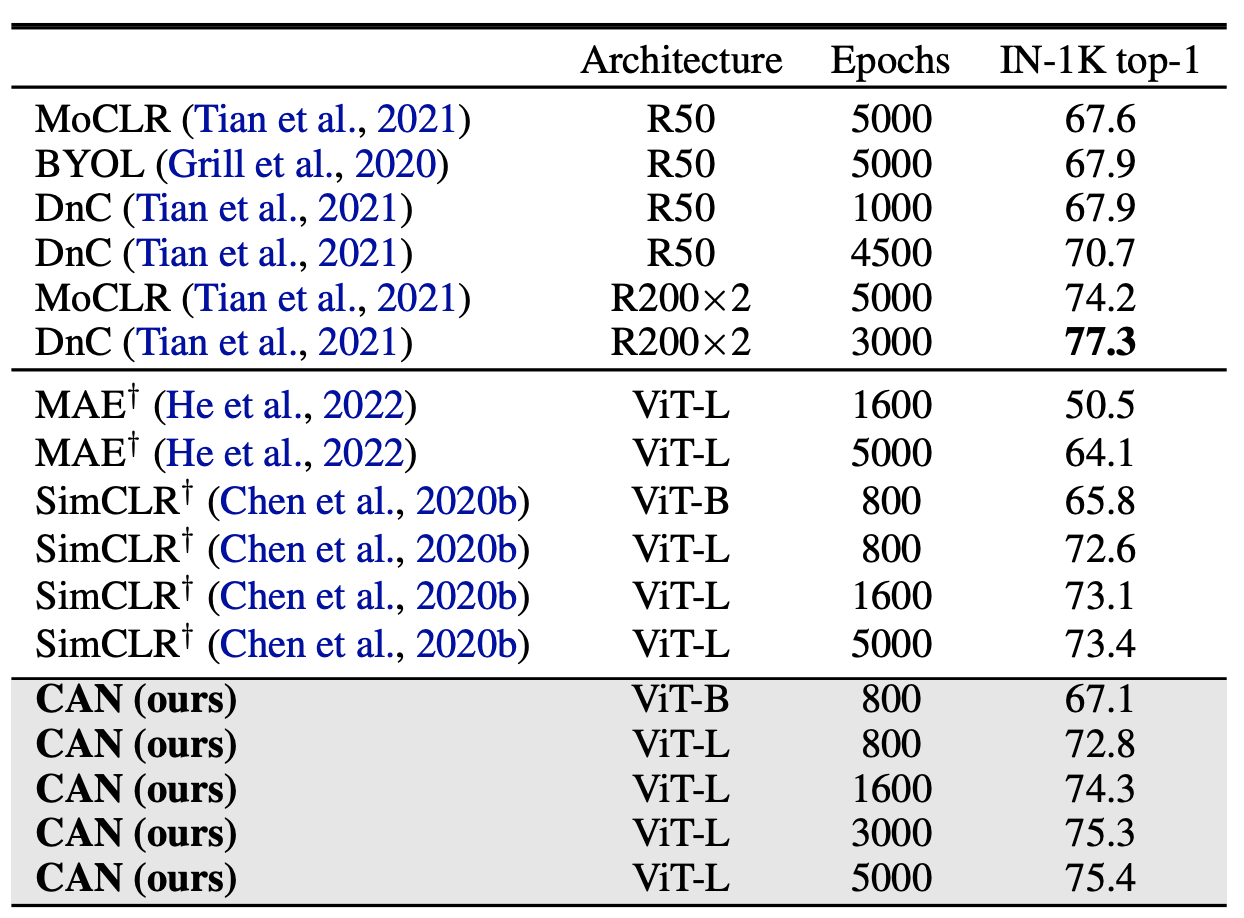
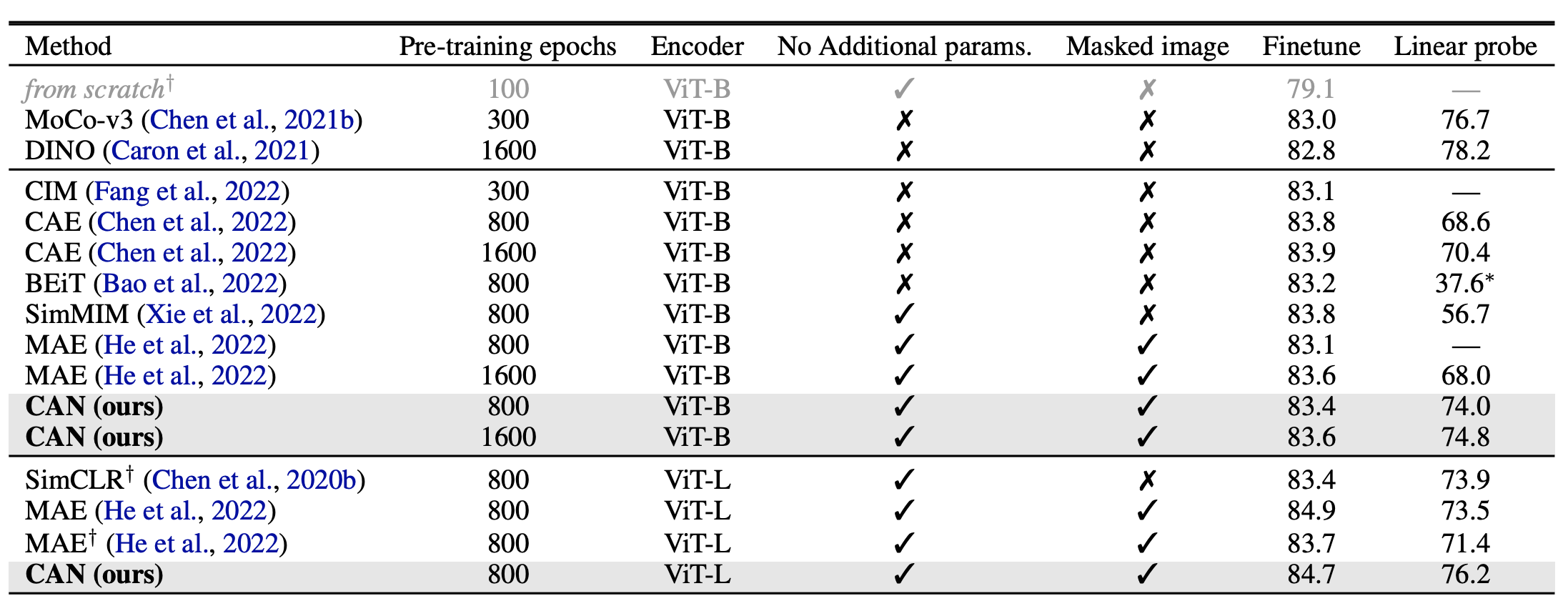
The results demonstrate improved or on-par performance with recent SSL methods as measured on ImageNet 1K when finetuning or when using linear probing, both with and without pre-training on JFT-300 [4] or on Imagenet [5]:
 |
|---|
| JFT-300M pre-training: Comparison to the state of the art on ImageNet linear probe. CAN outperforms all methods except DnC, which uses a complicated multi-stage training process. Computation is measured as ImageNet-equivalent epochs. †Our implementation. |
 |
|---|
| Pre-training on ImageNet-1K |
The results also show that the method scales well to JFT-300, hence the “scalable” part of the title. The method is also faster than methods which use the full image views, as it only “uses” 50% of the tokens in both views of the image (as opposed to SimCLR for example which augments the entire image) and does not use multiple views per image (such as DINO [6] or SwAV [7] which uses multi-crop), hence the “efficient” in the title. The paper is overall simple and elegant, does not use momentum encoder, hence the “simple” in the title. I should point out that it does not beat all other methods on all datasets, but the overall trade-off between results and simplicity is very good in my opinion. This is the main selling point of the paper: combining different semi-supervised techniques in a way which complement each other to obtain a unifed simple and efficient system. Keep in mind that the method can also be extended by adding a multiple views, momentum encoder or a tokenizer and a masking objective (as in BeiT[8]) to further improve the results, of course with the cost of complexity and slower running times.
References
[1] Chen, Ting, et al. “A simple framework for contrastive learning of visual representations.” International conference on machine learning. PMLR, 2020.
[2] He, Kaiming, et al. “Masked autoencoders are scalable vision learners.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[3] Ho, Jonathan, Ajay Jain, and Pieter Abbeel. “Denoising diffusion probabilistic models.” Advances in Neural Information Processing Systems 33 (2020).
[4] Sun, Chen, et al. “Revisiting unreasonable effectiveness of data in deep learning era.” Proceedings of the IEEE international conference on computer vision. 2017.
[5] Deng, Jia, et al. “Imagenet: A large-scale hierarchical image database.” 2009 IEEE conference on computer vision and pattern recognition, https://www.image-net.org/
[6] Caron, Mathilde, et al. “Emerging properties in self-supervised vision transformers.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[7] Caron, Mathilde, et al. “Unsupervised learning of visual features by contrasting cluster assignments.” Advances in Neural Information Processing Systems 33 (2020).
[8] Bao, Hangbo, et al. “BEiT: BERT Pre-Training of Image Transformers.” International Conference on Learning Representations. 2021.