
Text-Only Training for Image Captioning using Noise-Injected CLIP
Published:
Cool paper, simple and elegant. Training image captioning models commonly requires supervision in the form of image and text pairs. Given a text-only dataset (so no images and certainly no pairs), can we leverage CLIP’s [1] strong image and text embedding capabilities to train a text-only image captioning model? turns out we can.
As a reminder, given an image I with a corresponding text T, CLIP embeds I and T to a shared space where their embeddings are close. If we had image-text pairs, we could learn a decoder that given the CLIP image embedding as a starting point, reconstruct the text. However, in the above settings we don’t have access to images at training time, so the authors propose to use the text embedding as a proxy for the image embedding instead. Specifically, given a dataset of sentences, we extract CLIP text embeddings from each sentence and learn a decoder which reconstruct the text from the text embedding and in inference time simply apply the decoder on the input image embedding instead.
| Arxiv, Code, Keywords: CLIP, Image Captioning, Vision and Language, Venue: EMNLP 2022 |
|---|
This simple baseline performs poorly, as there is a gap between the image and the text embedding - the decoder is trained with the text embeddings, but in test time is applied to the image embeddings, which are close to the text embeddings, but not in the same position (for a given image-text pair).
Let us assume that for each image-text pair, the image embedding (which is given at test time) resides in a small epsilon neighbourhood around the text embedding. If we can learn a decoder that given a text embedding, decodes all vectors in its epsilon neighbourhood to the corresponding text, it would correctly decode the image embedding as well as it resides in its epsilon neighborhood. This is done in by adding a zero-mean Gaussian noise vector with STD epsilon to the text embedding during training. The value of epsilon is selected by taking the mean infinity norm between image embeddings and text embeddings of 15 images from MS-COCO [2]. The authors also provide an ablation study measuring the effect of epsilon on the performance (spoiler: pretty robust to the value of epsilon, as long as it’s not too deviated from the “correct” value, like an order of magnitude). Below is a figure providing an overview of the method, which the authors dubbed CapDec :
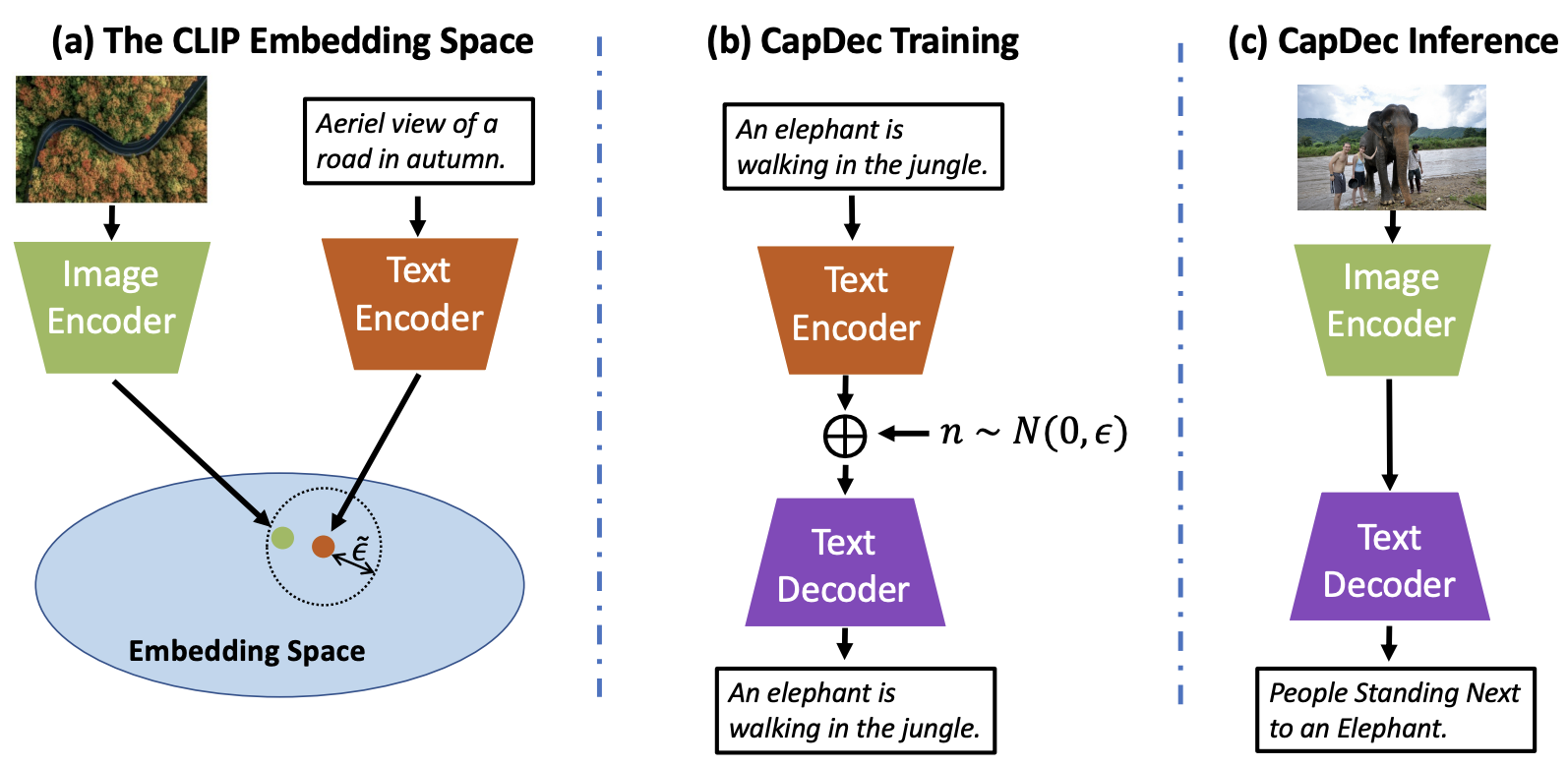 |
|---|
| Overview of CapDec captioning approach: . (a) An illustration of the CLIP joint embedding space. Embedded text is relatively close to its corresponding visual embedding, but with a certain gap. (b) CapDec trains a model that decodes the CLIP embedding of text T back to text T, after noise injection. The encoders remain frozen. (c) At inference, CapDec simply decodes the embedding of an image using the trained decoder. |
The method is tested on MS-COCO[2] and Flickr 30k[3] image captioning benchmarks and demonstrates a large improvement over other unsupervised or weakly supervised method. The method of course performance worse than state of the art supervised methods, but as an anecdote I checked, and it actually slightly outperforms “Show, Attend and Tell”[4] which was one of the seminal papers on image captioning.
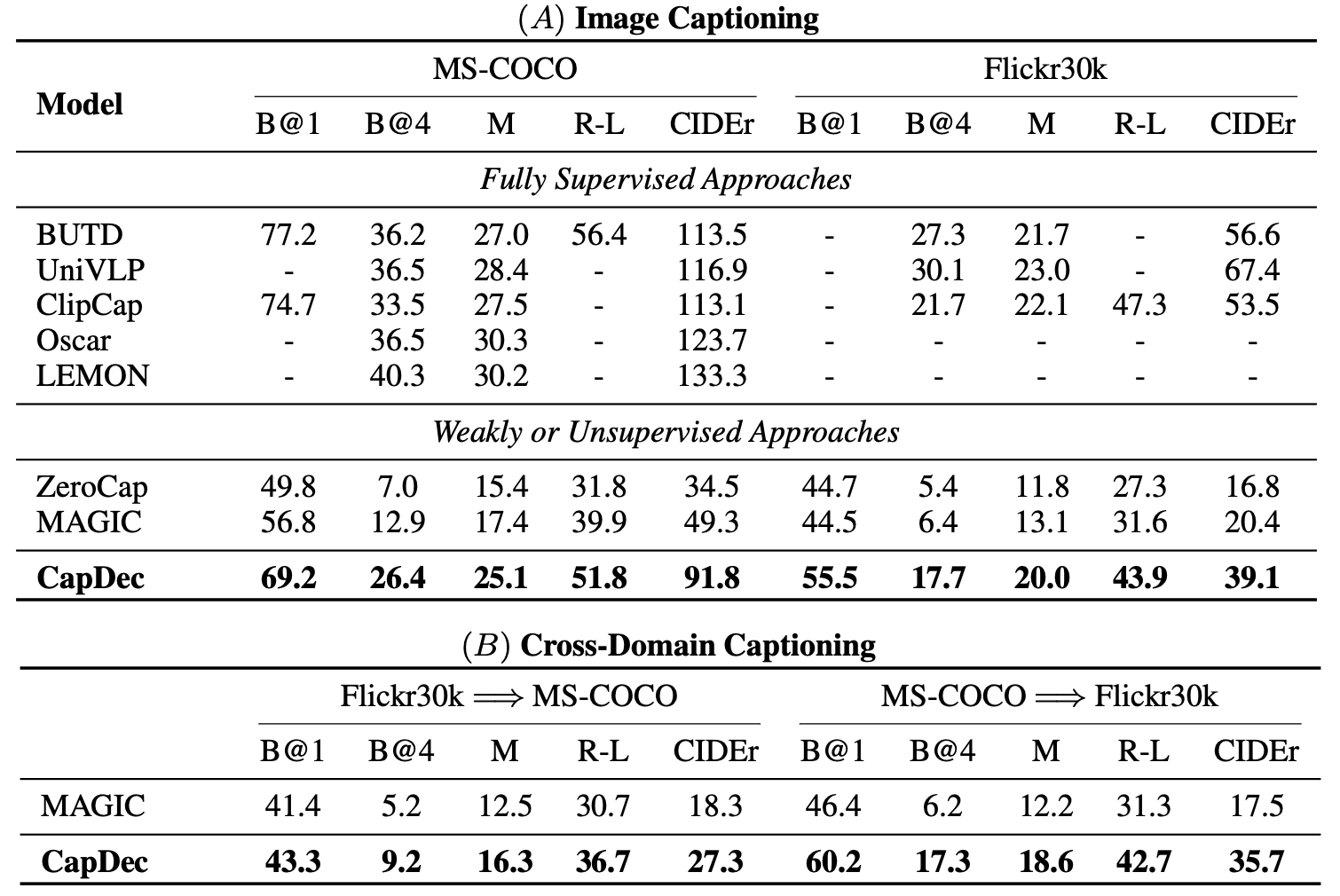 |
|---|
| Results for image captioning: . (A) We use captions from the COCO and Flickr30k to train CapDec and evaluate on the datasets the captions were taken from. We report results for fully supervised methods that train on captioned images, and on methods that use no training text (ZeroCap), or just training text and no images (CapDec and MAGIC). (B) Similar setting to (A), but in cross-domain setup where training text is taken from one dataset, and evaluation is done on the second dataset. |
The authors also show strong performance on style-guided image captioning, a task where the method requires to generate captions in a certain text style in which labeled image-text data can be limited. Those results are summarised below along with several examples:
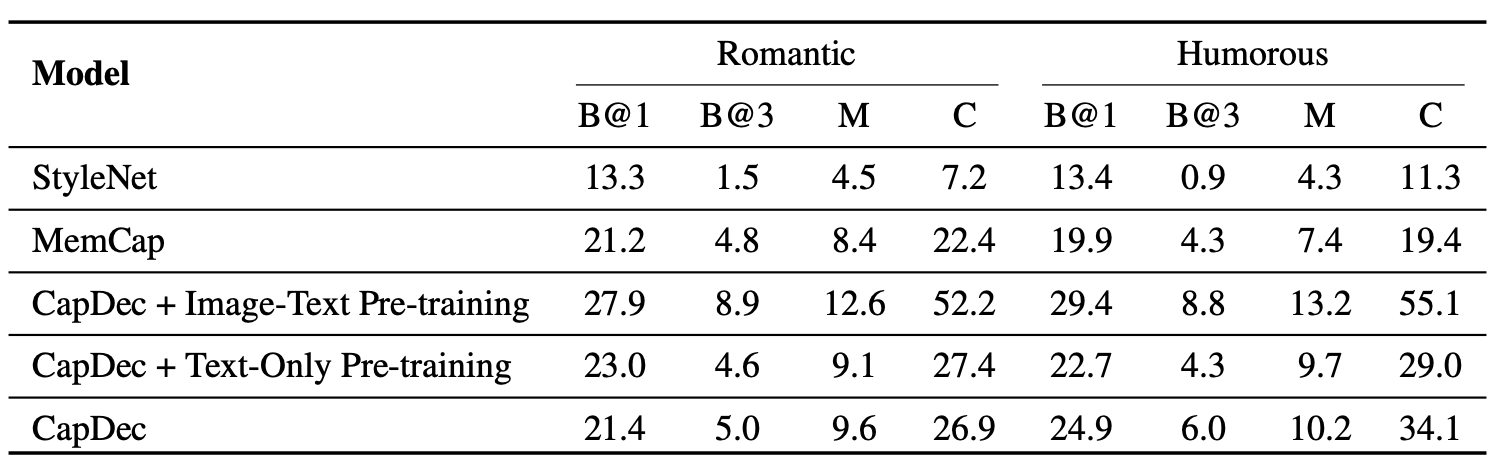 |
|---|
| Style-Guided captioning results on FlickrStyle10K: |
 |
|---|
| Example for styled captions of CapDec on FlickrStyle10K |
A similar method was recently proposed which also leverages CLIP to perform various image and language tasks without training on images by injecting noise to the text embedding during model training [5].
References
[1] Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International Conference on Machine Learning. PMLR, 2021.
[2] Lin, Tsung-Yi, et al. “Microsoft coco: Common objects in context.” European conference on computer vision. Springer, Cham, 2014.
[3] Young, Peter, et al. “From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions.” Transactions of the Association for Computational Linguistics 2 (2014).
[4] Xu, Kelvin, et al. “Show, attend and tell: Neural image caption generation with visual attention.” International conference on machine learning. PMLR, 2015.
[5] Gu, Sophia, Christopher Clark, and Aniruddha Kembhavi. “I Can’t Believe There’s No Images! Learning Visual Tasks Using only Language Data.” arXiv preprint arXiv:2211.09778 (2022).