
DeiT III: Revenge of the ViT
Published:
As hinted by the title, the paper is a follow-up work to DeiT (Training data-efficient image transformers & distillation through attention [1]) and co-authored by several of DeiT’s authors. The paper was presented at ECCV 2022, code is available here under the original DeiT repository. The goal of the paper is to provide an improved training recipe for “vanilla” Vision Transformers (ViT) [2] in order to achieve a stronger baseline for vanilla ViT, without any architectural changes. I find this approach very interesting as there is a large body of works which offer various architectural changes (some motivated by ConvNets) to vanilla ViT (e.g.: PVT[3], Swin[4], CvT[5], Focal Transformer[6], Coatnet[7]), and here the authors steer away from making any changes to the architecture and focus instead only on the training recipe. This work is also similar to a previous paper by the several of same authors, “ResNet strikes back: An improved training procedure in timm” [8] which offers an improved training receipt for ResNets to achieve a stronger baseline for simple “vanilla” ResNets. Fun fact, there is no DeiT2 !
| Arxiv, Code, Keywords: Vision Transformers, Training recipe, Venue: ECCV 2022 |
|---|
DeiT III is sort of a response to several lines of work: improved ViT architectures such as Swin [9], improved ConvNet architecture such as ConvNext [10] and self-supervised training methods for ViT such as BEiT [11]. The paper suggest several training strategies that improve ViT performance such that training scales to larger model size without saturating, training time is reduced and the final models reach better or on par performance with Swin[9], ConveNext[10] and other recent architecture as well using “BeiT[11]-like” training when benchmarked on ImageNet 1K, ImageNet 21K and downstream tasks.
The training strategy is composed of following techniques:
- Stochastic Depth [12] which randomly drops layers in the network during training.
- LayerScale[13] which normalizes each channel of the matrix produced by Multi-Head Self Attention (MSHA) and Feed Forward Network (FFN) blocks using a different learned constant.
- Replacing Cross Entropy (CE) with Binary Cross Entropy similarly to [8] which provides an improvement in some experiments. Using the LAMB [14] optimizer.
- 3-Augment: a simple augmentation method composed of either grayscaling, solarization or Gaussian blur (with equal probability) followed by color jittering and horizontal flip.
- Simple Random Crop: which resizes the input image such that the smallest side matches the training resolution and randomly samples square crops in that resolution.
Below is a table summarizing the training recipe, including all hyperparameters and compares it to previous methods:
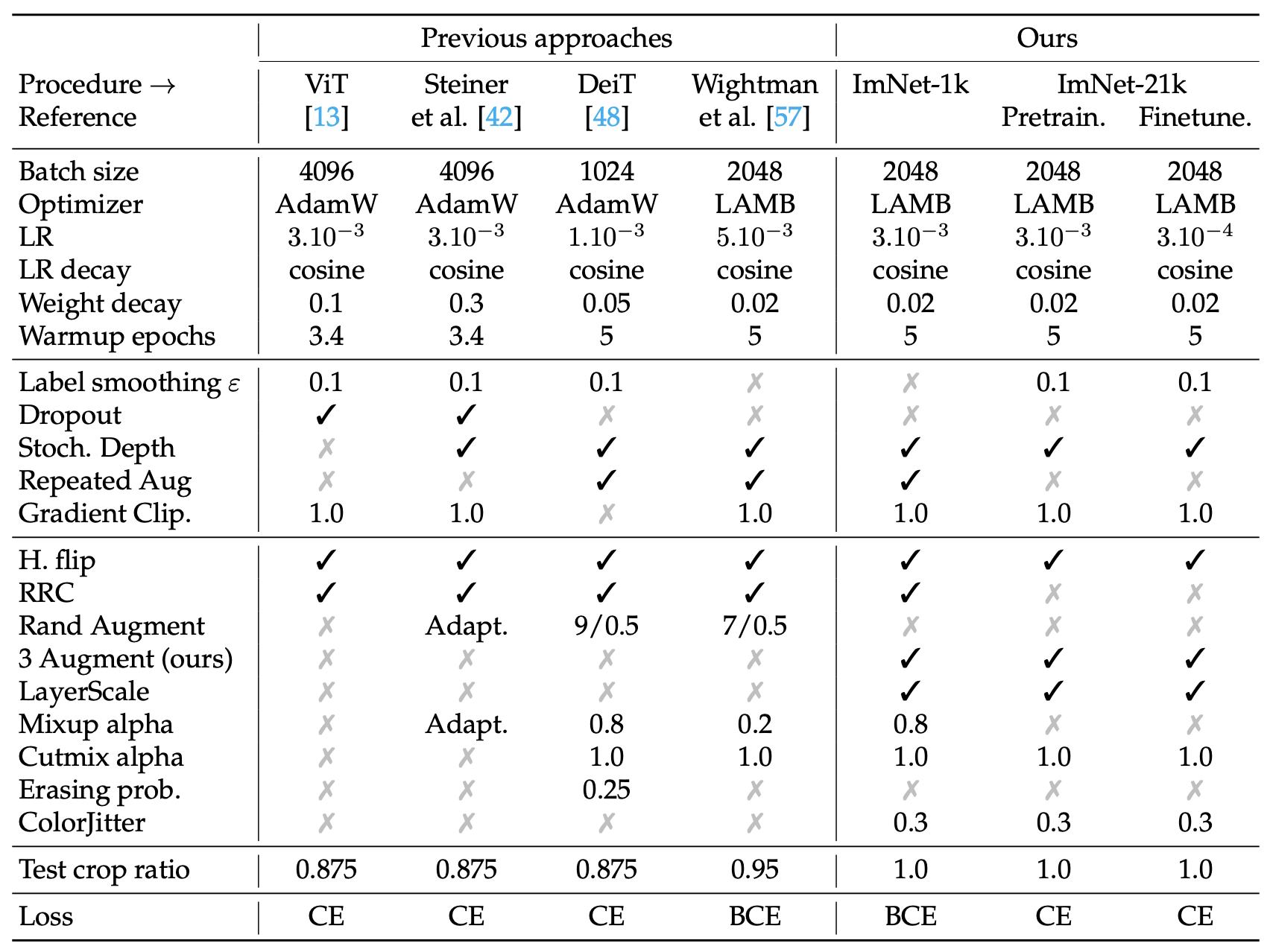 |
|---|
| Comparison of Deit3 training recipes including all hyperparameters |
The paper presents several experiments demonstrating the effectiveness of the improved training recipe. First, they show a significant improvement gap compared to vanilla ViT and DeiT training recipes, measured on ImageNet 1k and ImageNet 21k:
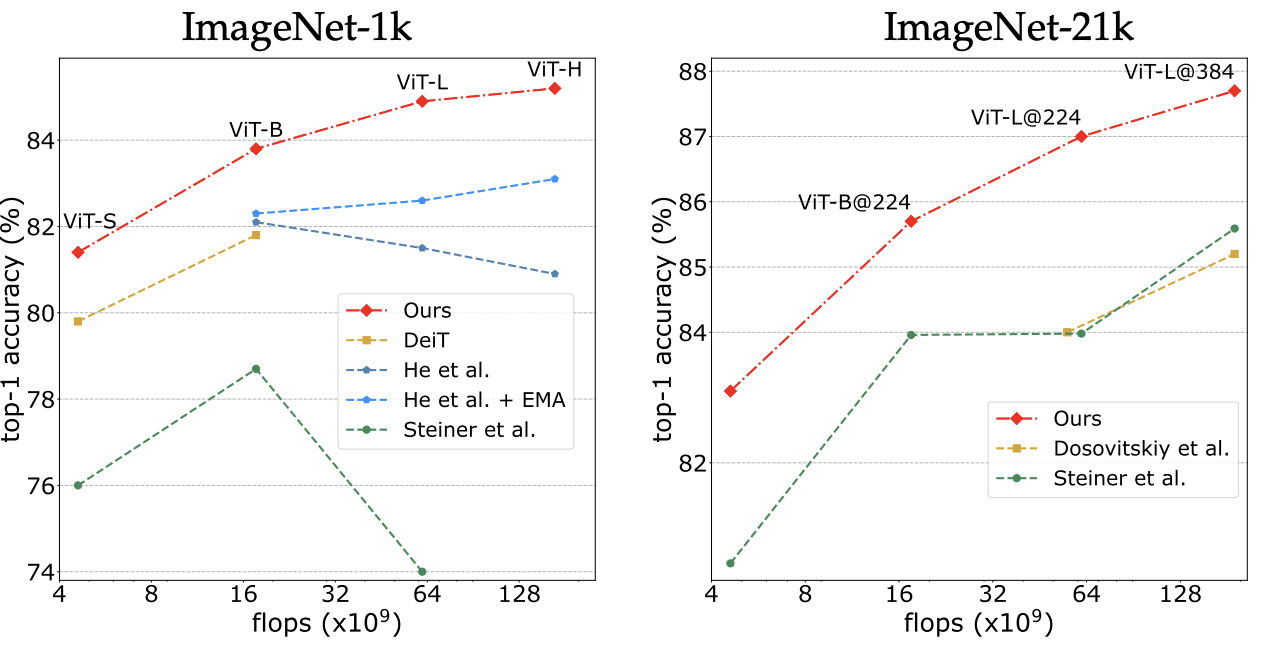 |
|---|
| Comparison of training recipes for (left) vanilla vision transformers trained on ImageNet-1k and evaluated at resolution 224×224, and (right) pre-trained on ImageNet-21k at 224×224 and finetuned on ImageNet-1k at resolution 224×224 or 384×384. |
In addition, the paper demonstrates on-par performance with recent architectures, such as ConvNext and Swin, measured on ImageNet 1k and ImageNet 21k, see tables below:
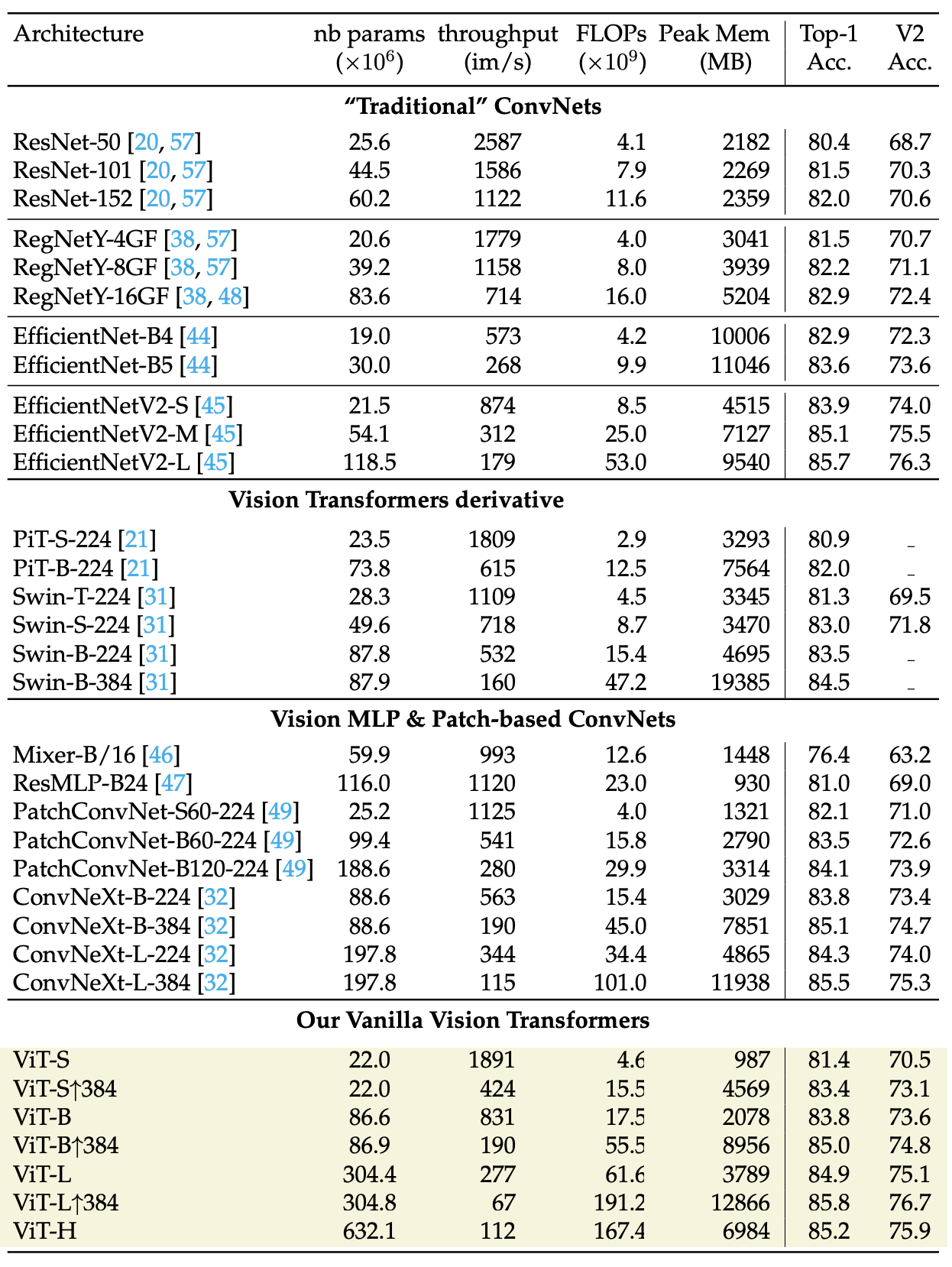 |
|---|
| Classification with Imagenet-1k training: The authors compare architectures with comparable FLOPs and number of parameters. All models are trained on ImageNet1k only without distillation nor self-supervised pre-training. We report Top-1 accuracy on the validation set of ImageNet1k and ImageNetV2 with different measure of complexity: throughput, FLOPs, number of parameters and peak memory usage. The throughput and peak memory are measured on a single V100-32GB GPU with batch size fixed to 256 and mixed precision. The reslts ResNet and RegNet from the “Resnet strikes back” paper [20]. Note that different models may have received a different optimization effort, so this is not a complete “apples to apples” comparison. ↑R indicates that the model is fine-tuned at the resolution R and -R indicates that the model is trained at resolution R. |
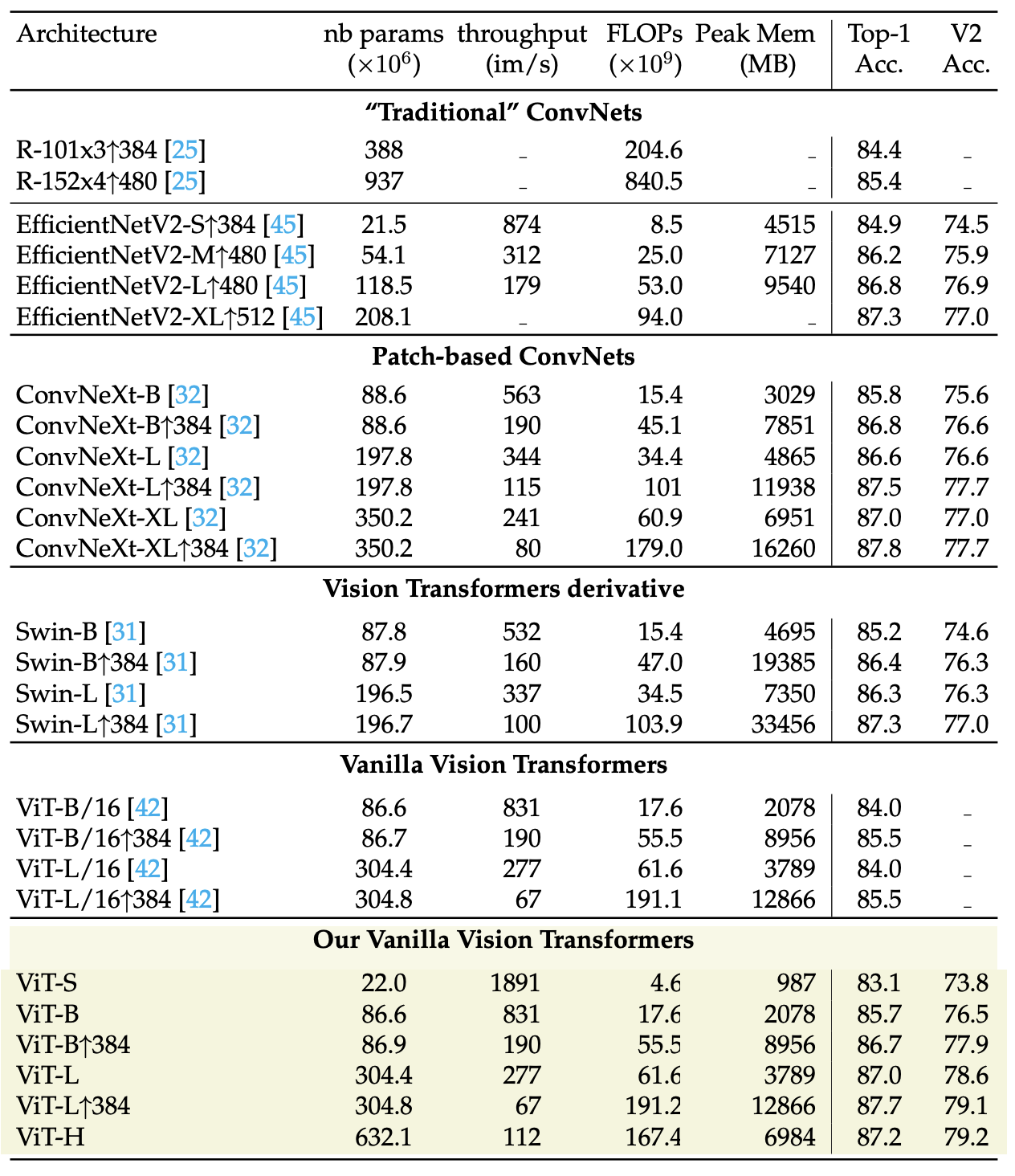 |
|---|
| Classification with Imagenet-21k training: The authors compare architectures with comparable FLOPs and number of parameters. All models are trained on ImageNet1k only without distillation nor selfsupervised pre-training. We report Top-1 accuracy on the validation set of ImageNet1k and ImageNetV2 with different measure of complexity: throughput, FLOPs, number of parameters and peak memory usage. The throughput and peak memory are measured on a single V100-32GB GPU with batch size fixed to 256 and mixed precision. For Swin-L the authors decrease the batch size to 128 in order to avoid out of memory error and re-estimate the memory consumption. ↑R indicates that the model is fine-tuned at the resolution R. |
As written above, the paper is also a response to self-supervised training methods, thus the authors also compared their improved supervised training recipe to self-supervised alternatives, specifically MAE [15] and BeiT[11]:
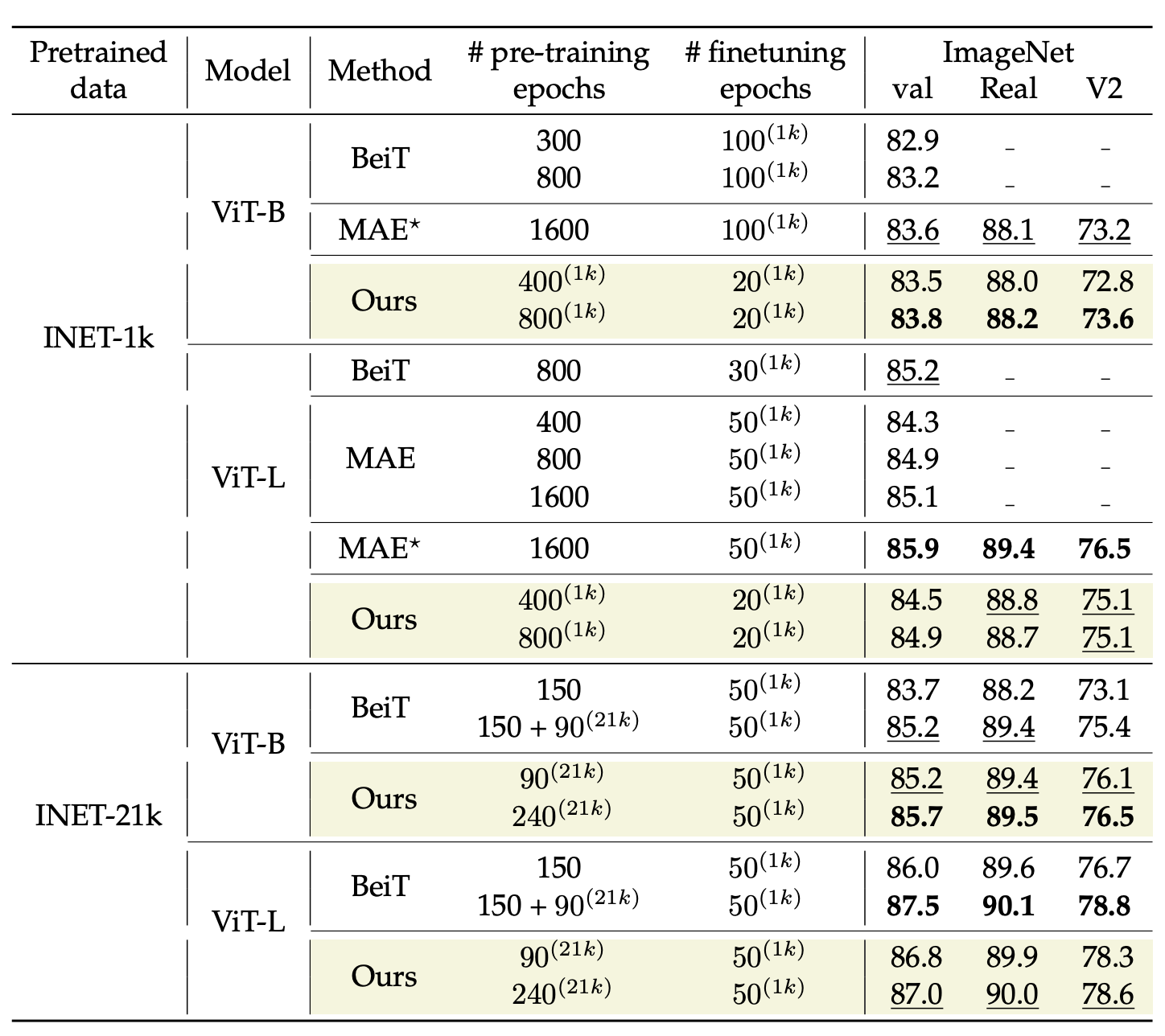 |
|---|
| Comparison of self-supervised pre-training with DeiT3 approach. Please note that DeiT3 training is full supervised whereas MAE and BeiT are self-supervised pre-training methods, so this is not a direct comparison of fully supervised training recipes, but more of trainining “stratagies”. All models are evaluated at resolution 224 × 224. Results are reported on ImageNet Val, real and v2 in order to evaluate overfitting. The superscripts (21k) and (1k) indicate finetuning with labels on ImageNet-1k and Imagenet-21k, respectively. |
The paper also demonstrates improved performance in transfer learning on semantic segmentation, measured on ADE20k [16] dataset:
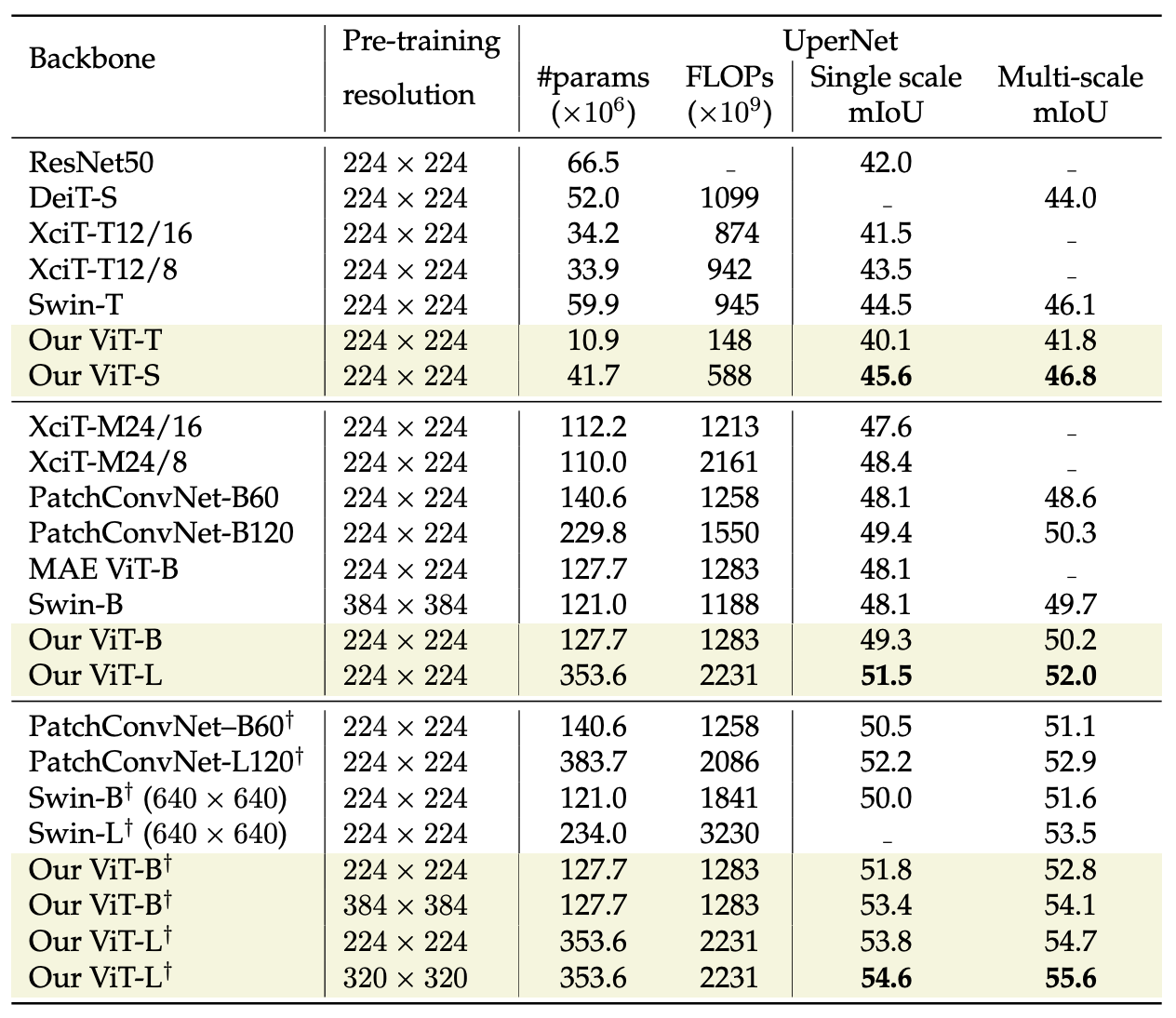 |
|---|
| ADE20k semantic segmentation. All models are pre-trained on ImageNet-1k except models with † symbol that are pre-trained on ImageNet-21k. The authors report the pre-training resolution used on ImageNet-1k and ImageNet-21k. |
All in all, at first sight DeiT 3 might seem like a “bag of tricks” sort of paper and one might argue that it does not hold enough technical novelty to be presented at a top-tier conference such as ECCV. In my opinion, this is hardly the case. While the novelty is limited (and the authors do not argue otherwise in the text), saying “hey, you can get very good results with vanilla ViT just by improving the training procedure with no architectural changes (or bells and whistles)” is a strong contribution in my opinion.
References
[1] Touvron, Hugo, et al. “Training data-efficient image transformers & distillation through attention.” International Conference on Machine Learning. PMLR, 2021.
[2] Dosovitskiy, Alexey, et al. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
[3] Wang, Wenhai, et al. “Pyramid vision transformer: A versatile backbone for dense prediction without convolutions.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[4] Liu, Ze, et al. “Swin transformer: Hierarchical vision transformer using shifted windows.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[5] Wu, Haiping, et al. “Cvt: Introducing convolutions to vision transformers.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[6] Yang, Jianwei, et al. “Focal self-attention for local-global interactions in vision transformers.” arXiv preprint arXiv:2107.00641 (2021).
[7] Dai, Zihang, et al. “Coatnet: Marrying convolution and attention for all data sizes.” Advances in Neural Information Processing Systems 34 (2021).
[8] Wightman, Ross, Hugo Touvron, and Hervé Jégou. “Resnet strikes back: An improved training procedure in timm.” arXiv preprint arXiv:2110.00476 (2021).
[9] Liu, Ze, et al. “Swin transformer: Hierarchical vision transformer using shifted windows.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[10] Liu, Zhuang, et al. “A convnet for the 2020s.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[11] Bao, Hangbo, et al. “BEiT: BERT Pre-Training of Image Transformers.” International Conference on Learning Representations. 2021.
[12] Huang, Gao, et al. “Deep networks with stochastic depth.” European conference on computer vision. Springer, Cham, 2016.
[13] Touvron, Hugo, et al. “Going deeper with image transformers.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[14] You, Yang, et al. “Large batch optimization for deep learning: Training bert in 76 minutes.” arXiv preprint arXiv:1904.00962 (2019)
[15] He, Kaiming, et al. “Masked autoencoders are scalable vision learners.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[16] Zhou, Bolei, et al. “Scene parsing through ade20k dataset.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.