
Fast Vision Transformers with HiLo Attention
Published:
The paper proposes a novel efficient ViT architecture with throughput in mind to mitigate ViT’s high computational complexity which stems from the quadratic memory and time complexity of the attention mechanism. First, the paper argue (and in my opinion rightfully so) that although many improved and more efficient ViT architectures have been proposed, in practice they do not offer high processing speed. This claim might seem contradictory, but in fact previous works usually consider metrics such as number of FLOPS, memory usage and asymptotic computational complexity (which are important by themselves), but those metrics do not capture the actual running time or throughput nor those works directly measure those. Moreover, specific architectures with small number of FLOPS and memory requirements or lower asymptotic complexity as might actually run slowly when implemented on GPU due to specific operations which not hardware-friendly or cannot be parallelized. To this end, the paper directly benchmarks FLOPS and memory consumption as well as throughput (on GPU) and proposes a ViT architecture that performs favourably in those metrics while achieving high accuracy when used as backbone in classification and various down-stream vision tasks.
| arxiv, code , keywords: Vision Transformers, Efficient Attention, Venue: Neurips 2022 spotlight paper |
|---|
The proposed ViT architecture is based on changing the attention mechanism by separating the self-attention heads into two groups. One group (1-$\alpha$) of the heads performs self-attention in local windows on the original high resolution feature map (denoted Hi-Fi attention), thus capturing fine details in small local windows (characterised by high frequencies) while the second group performs regular global self attention but on a downscaled (max-pooled) version of the feature map (denoted Lo-Fi attention) to captured global structures (characterised by low frequencies). The feature-maps from the two groups are concatenated and passed to the next HiLo attention block.
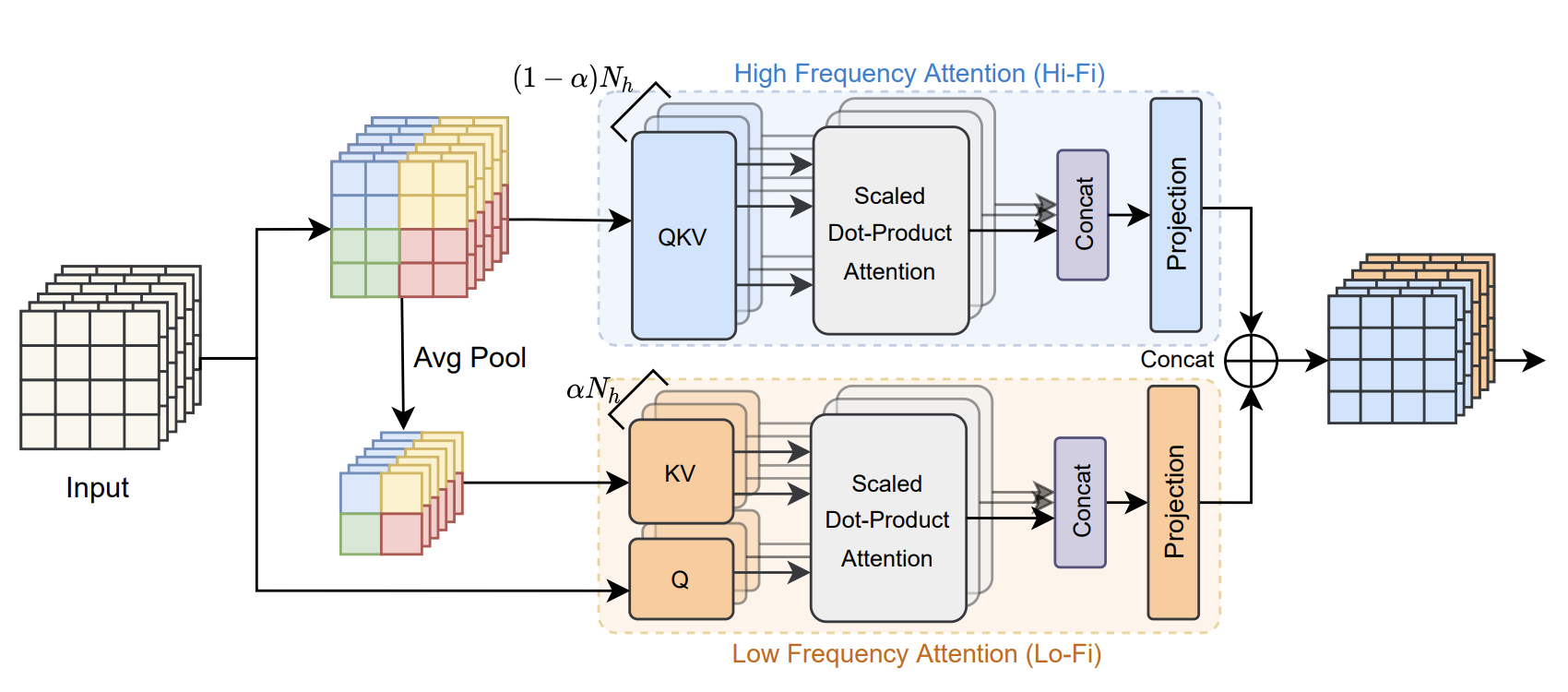 |
|---|
| Framework of HiLo attention: $N_h$ refers to the total number of self-attention heads at this layer. $\alhpa$ denotes the split ratio for high/low frequency heads. |
The authors provide an ablation study measuring the effect of different choices of $\alpha$ (see figure below). As $\alpha$ increases, the fraction of heads allocated to the second group performing global attention on the downscaled feature map increases, bringing more “attention” (apologies for the “notation overloading”) to global structures. This also reduces FLOPS and improves the running time as Lo-Fi attention has lower computational complexity than Hi-Fi attention. The authors find that the best performance is obtained when $\alpha=0.9$, meaning 90% of the heads perform global attention on the downscaled features maps and only 10% of the heads attend to local fine details. Interestingly, setting $\alpha=1.0$, meaning essentially removing the Hi-Fi attention and replacing the method with regular attention on downscaled feature maps performs competitively on ImageNet1K[1], but the authors report it provides worse results on dense prediction tasks such as semantic segmentaion (however, the authors do not provide an ablation using semantic segmentation, as far as I can tell).
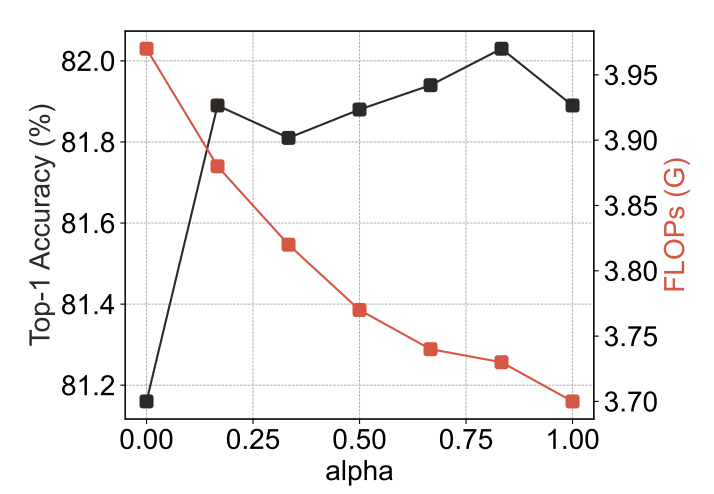 |
|---|
| Effect of $\alpha$ based on LITv2-S |
The authors compare the proposed architecture with recent ViT and Convnet architectures on as backbone for Image Classification on ImageNet-1K, Object Detection and Instance Segmentation on COCO[2] and Semantic Segmentation on ADE20K[3], demonstrating on-par (or better) accuracy against state-of-the-art methods while providing high throughput and a small memory footprint.
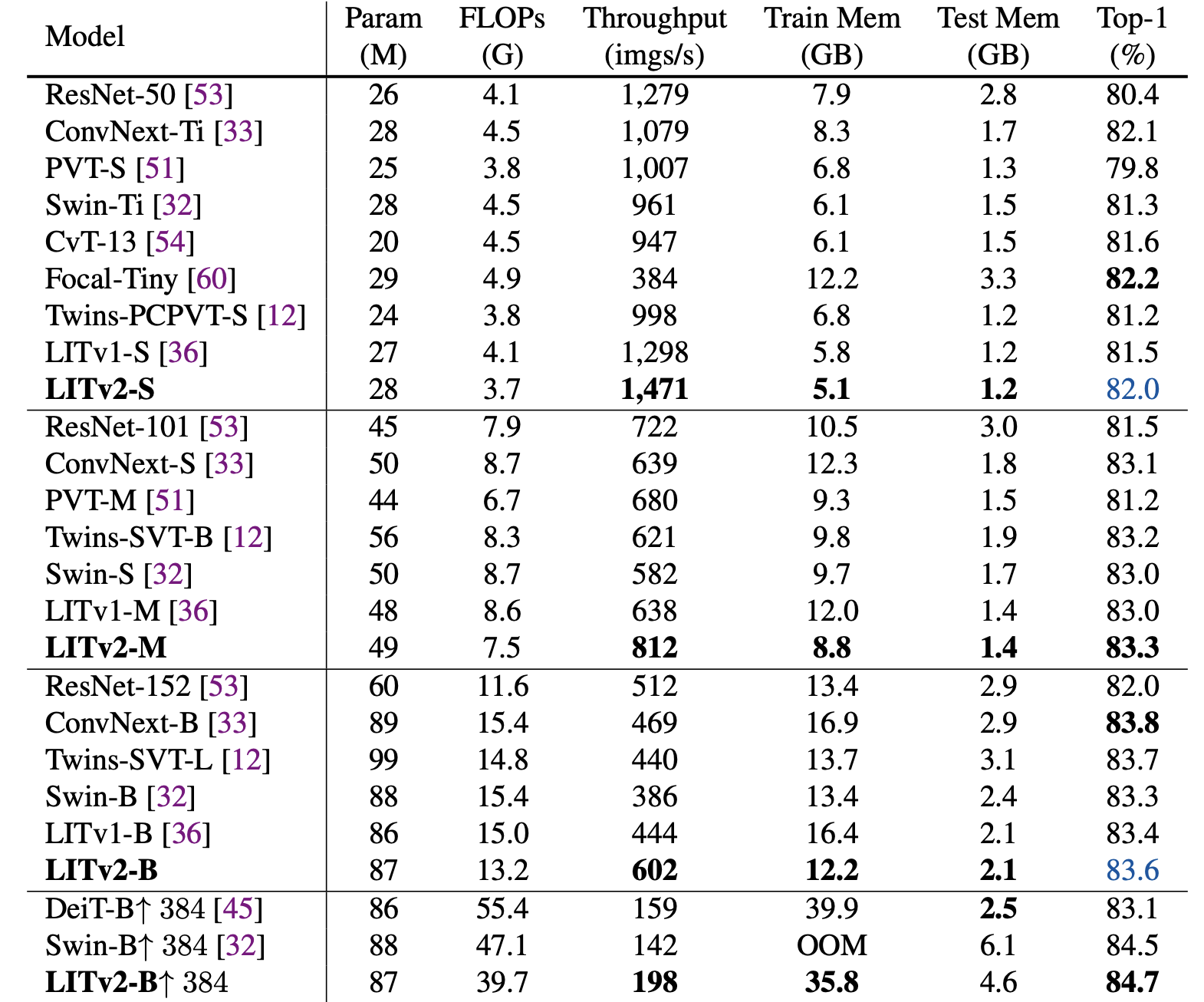 |
|---|
| Image classification results on ImageNet-1K: By default, the FLOPs, throughput and memory consumption are measured based on the resolution 224 × 224 with a batch size of 64. Throughput is tested on one NVIDIA RTX 3090 GPU and averaged over 30 runs. ResNet results are take from “ResNet Stikes Back” [4], “↑ 384” means a model is finetuned at the resolution 384 × 384. “OOM” means “out-of-memory”. |
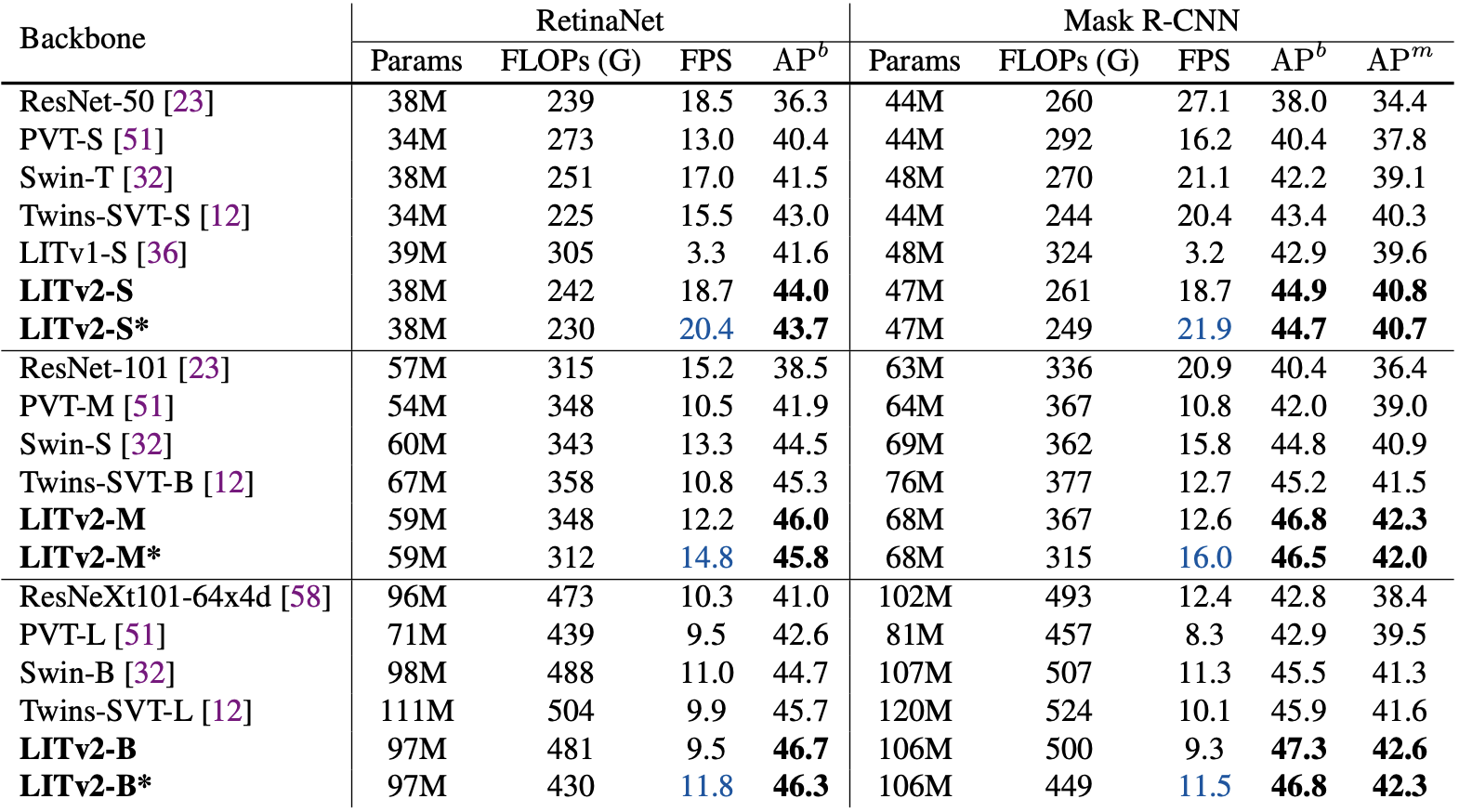 |
|---|
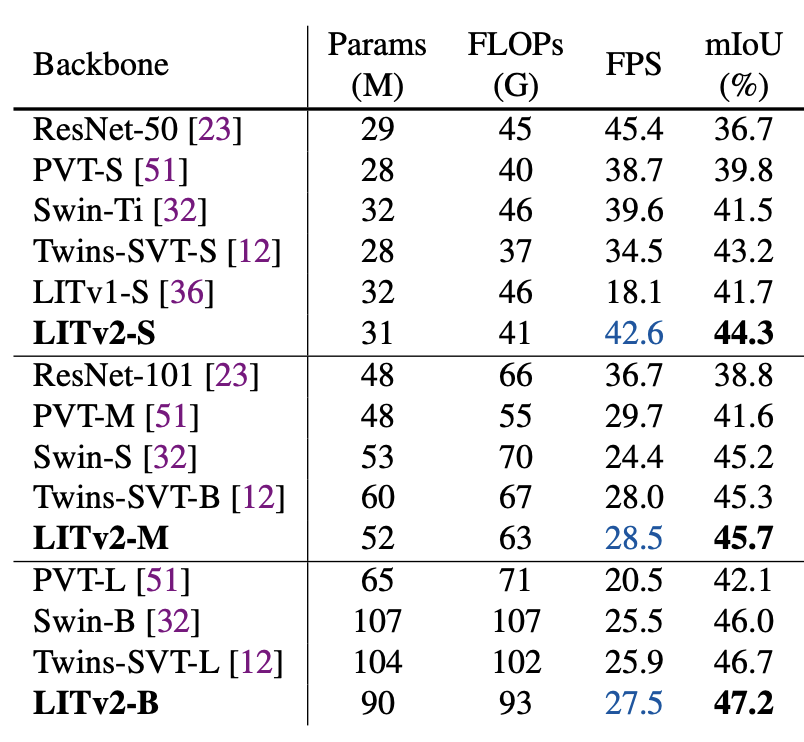
| Object detection and instance segmentation performance: performance is measured on the COCO val2017 split using the RetinaNet and Mask R-CNN framework. $AP^b$ and $AP^m$ denote the bounding box AP and mask AP, respectively. * indicates the model adopts a local window size of 4 in HiLo. |
 |
|---|
| Semantic segmentation performance of different backbones on the ADE20K validation set. FLOPs is evaluated based on the image resolution of 512 × 512. |
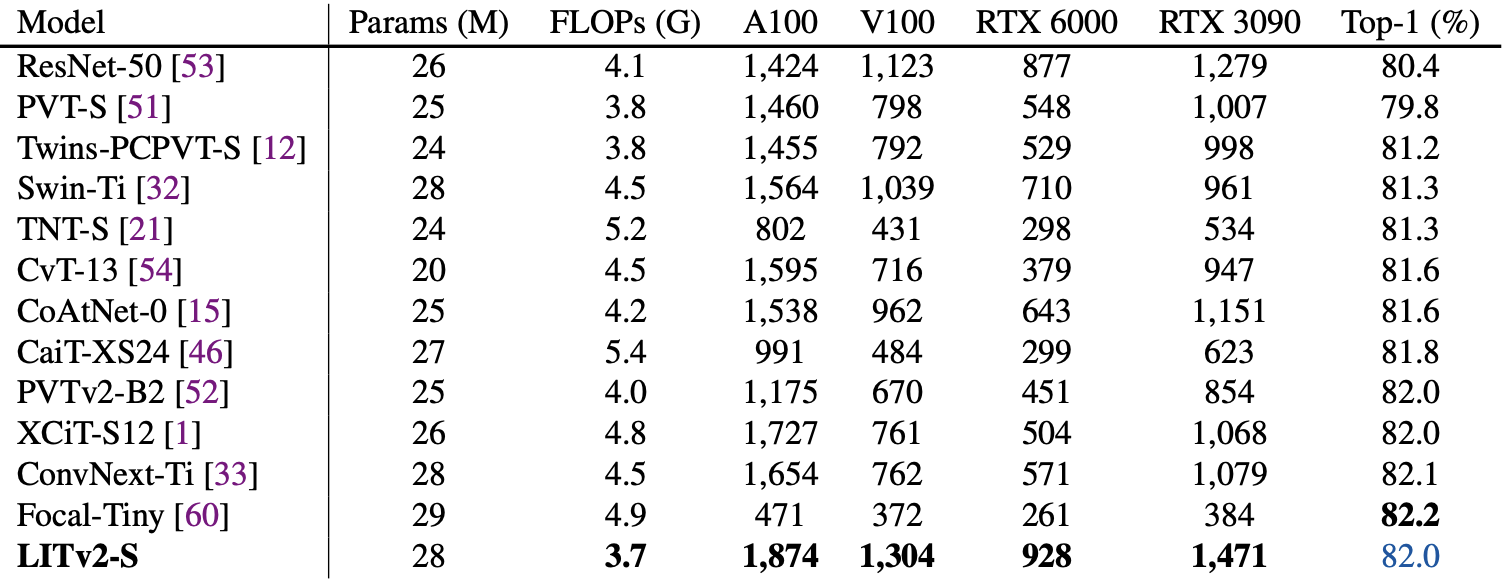
The authors further compare their proposed architecture against a wider array of more recent and stronger ViT architectures implemented across various different GPU models. The HiLo transformer achieves higher throughput (i.e.: faster running times) than all other methods on across all GPU models while still achieving almost the highest top-1 accuracy on ImageNet-1K.
 |
|---|
| Speed and performance comparisons between LITv2-S (HiLo transformer) and other recent ViTs on different GPUs. All throughput results are averaged over 30 runs with a total batch size of 64 and image resolution of 224 × 224 on one GPU card. Top-1 accuracy on ImageNet-1K is reported in the rightmost column. |
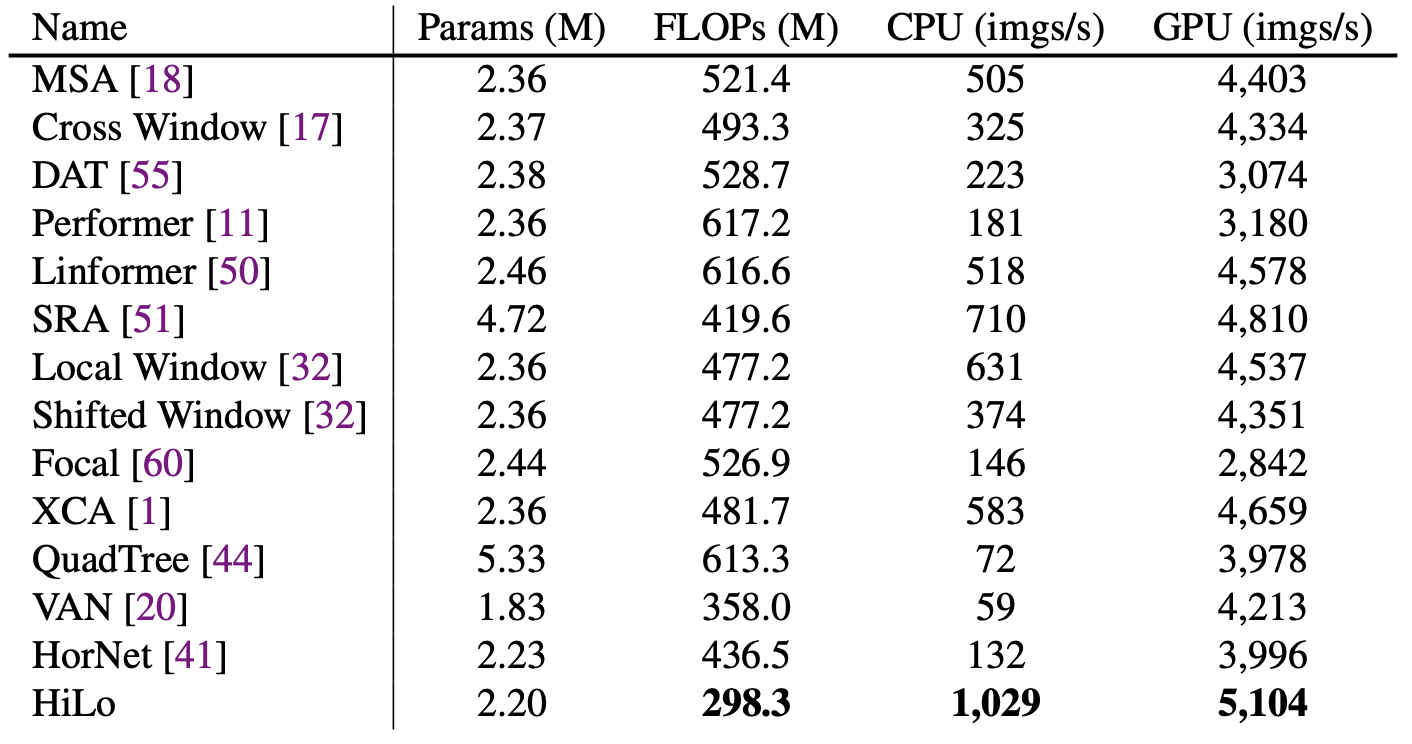
Overall, the paper presents a simple and efficient ViT attention mechanism, with an emphasis on having a “GPU friendly” implementation that achieves high throughput. There was a similar paper presented in ECCV with the same motivation, that considers efficient ViT architectures for edge devices: EdgeViTs: Competing Light-Weight CNNs on Mobile Devices with Vision Transformers (arxiv).
 |
|---|
| Throughput benchmark for different attention mechanisms based on a single attention layer. The authors report the throughput on both CPU (Intel® Core™ i9-10900X CPU @ 3.70GHz) and GPU (NVIDIA GeForce RTX 3090). |
References
[1] Deng, Jia, et al. “Imagenet: A large-scale hierarchical image database.” 2009 IEEE conference on computer vision and pattern recognition, https://www.image-net.org/
[2] Lin, Tsung-Yi, et al. “Microsoft coco: Common objects in context.” European conference on computer vision. Springer, Cham, 2014.
[3] Zhou, Bolei, et al. “Scene parsing through ade20k dataset.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[4] Wightman, Ross, Hugo Touvron, and Hervé Jégou. “Resnet strikes back: An improved training procedure in timm.” arXiv preprint arXiv:2110.00476 (2021).